

以前、訪問介護事業所向けにLINEのテキスト自動応答システムをn8nで構築した記録を公開しました。今回はそのアップデート版として、利用者・ご家族からの音声メッセージにも対応できるよう、Whisper・ElevenLabs・Claudeを組み合わせて音声会話機能を実装しました。
ご家族世代はLINEのテキストで問い合わせる方が多い一方で、高齢のご家族や音声入力に慣れた方からは「文字を打つのが大変なので音声で送りたい」というご要望がありました。本記事は、その音声対応をn8nのワークフローに追加していく実装記録です。
この記事で扱う内容
実装の前提となる技術スタック、ワークフロー全体のアーキテクチャ、各ノードの設定手順、そして実装中に遭遇した詰まりやすいポイントまで、再現性のある形で記録しました。これからn8nで類似の音声AIアシスタントを構築する方の参考になれば幸いです。
実装の最大のポイントは以下の3つです。
① 当社にとってこれまでで最も規模の大きいn8nワークフローになりました。ノード数が10個を超え、IF・Switch・Mergeなどの条件分岐を多用し、Supabase上で依存関係のある複数テーブルを設計しました。これらは個別に経験はあったものの、1つのプロジェクトで全てを組み合わせるのは初めてです。
② 個人情報マスキング処理。介護現場では利用者氏名・住所・電話番号などのセンシティブ情報がメッセージに含まれることが多いため、Claude APIに渡す前にマスキングする工程を入れました。
③ 二段階のリスク検知レイヤー。利用者の「死にたい」「倒れた」などの発言をAIが軽率に応答してしまわないよう、キーワードマッチと軽量LLM分類の二段構えで検知し、検知時はAI応答を停止して担当者にEメールで連絡する設計です。
全体アーキテクチャ
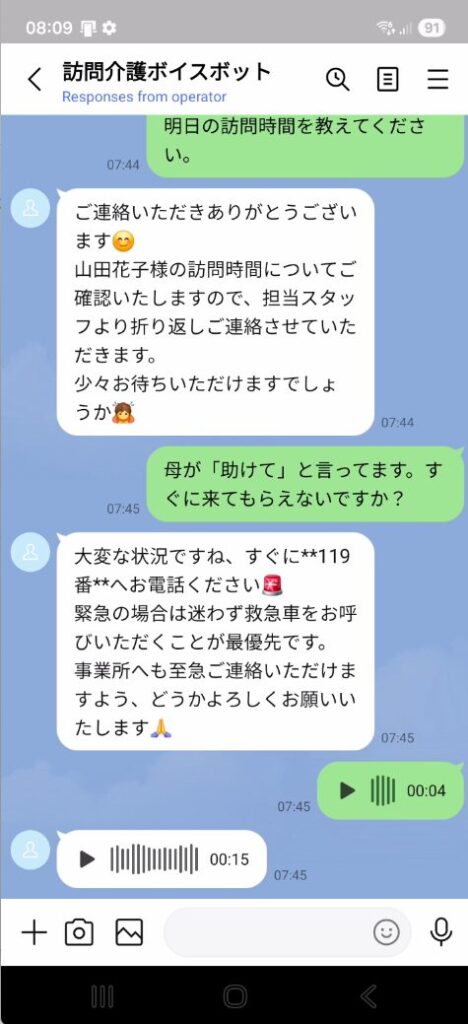
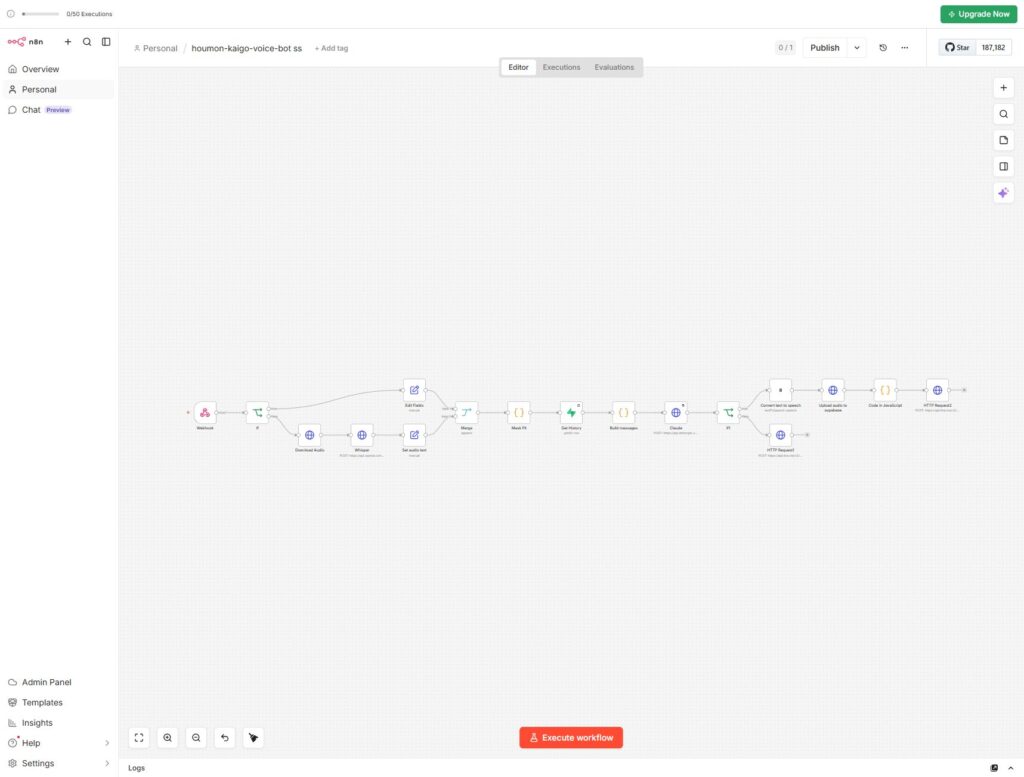
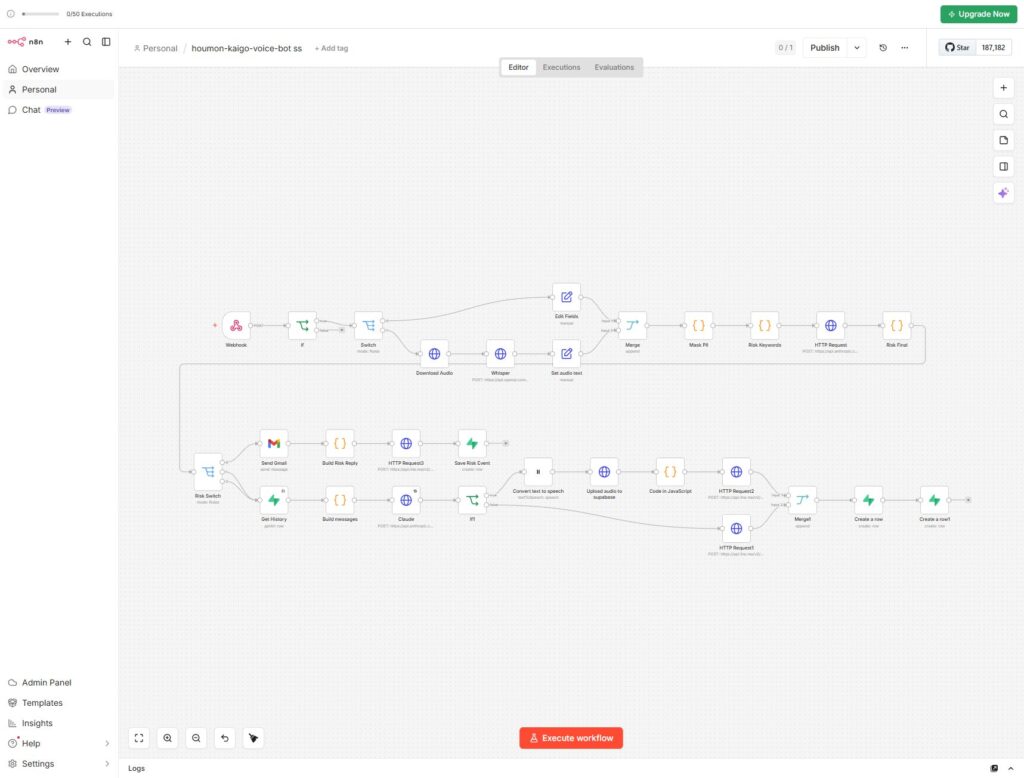
完成したワークフローの全体像は以下の通りです。
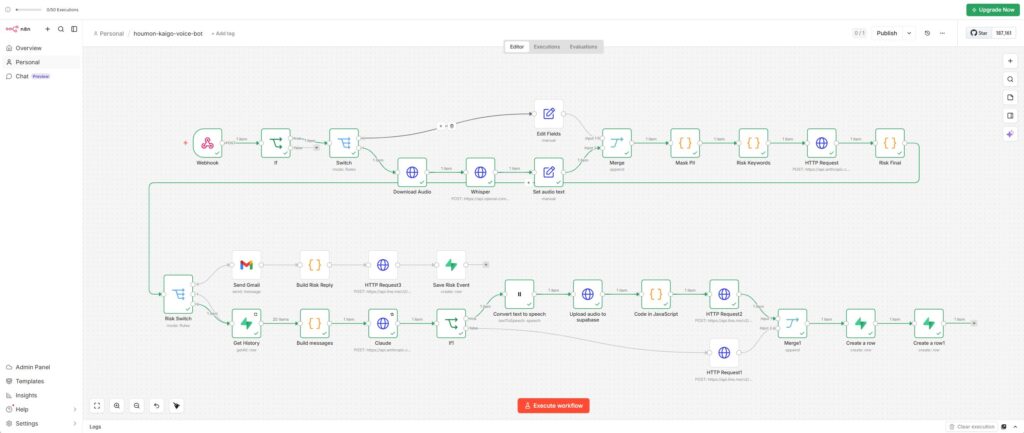
LINE Messaging API(音声メッセージ受信)
↓
n8n Webhook
↓
イベント種別判定(テキスト or 音声)
↓ ※音声の場合
LINE音声ファイルダウンロード → Whisper API(文字起こし)
↓
個人情報マスキング処理
↓
リスク検知レイヤー(キーワード + Claude Haiku)
├─ 高リスク → Gmail通知 + 定型テキスト返信
└─ 通常 → 会話履歴取得 → Claude Sonnet応答生成
↓
ElevenLabs(音声合成)
↓
Supabase Storage(音声ファイル保管)
↓
LINE Messaging API(音声メッセージ返信)使用したサービスは以下の通りです。
| サービス | 用途 |
|---|---|
| LINE Messaging API | メッセージ送受信 |
| n8n(Railway) | ワークフロー実行基盤 |
| OpenAI Whisper API | 音声→テキスト変換 |
| Anthropic Claude API | 応答生成・リスク分類 |
| ElevenLabs | テキスト→音声合成 |
| Supabase | DB・音声ファイル保管 |
事前準備:アカウントとAPIキーの取得
実装に入る前に、以下のサービスのアカウントを作成し、APIキーを取得しました。所要時間は2〜3時間です。
LINE Messaging APIの有効化
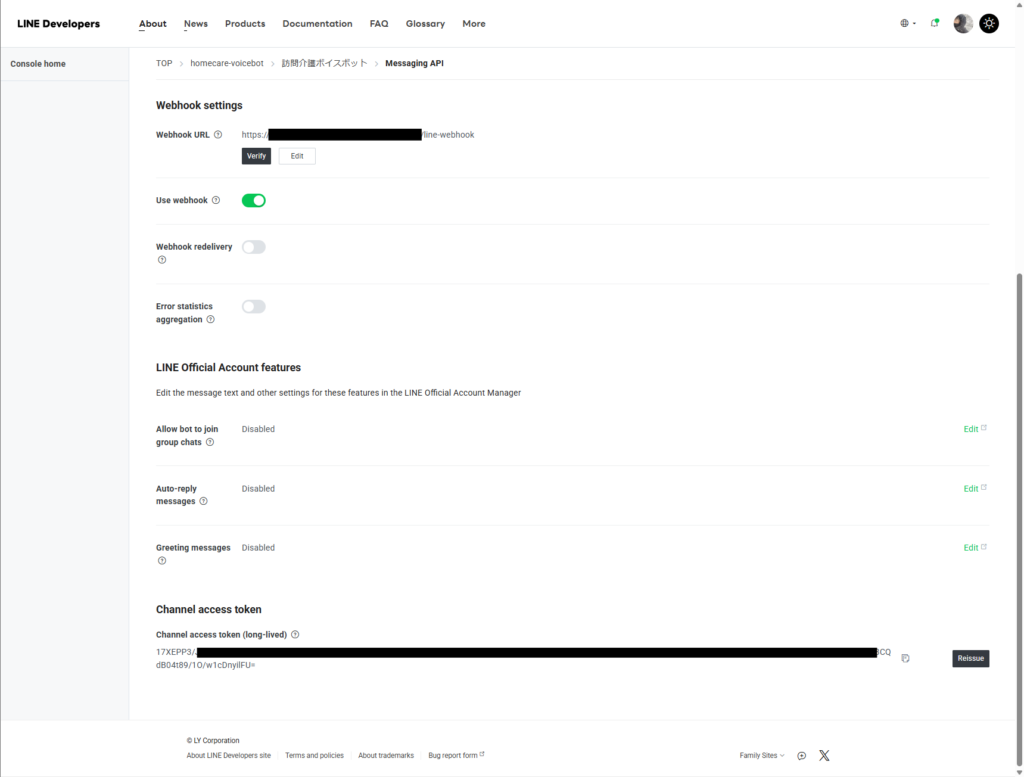
LINE Official Account Manager(manager.line.biz)でMessaging APIを有効化します。設定→Messaging APIから「Messaging APIを利用する」を実行し、プロバイダーを選択。
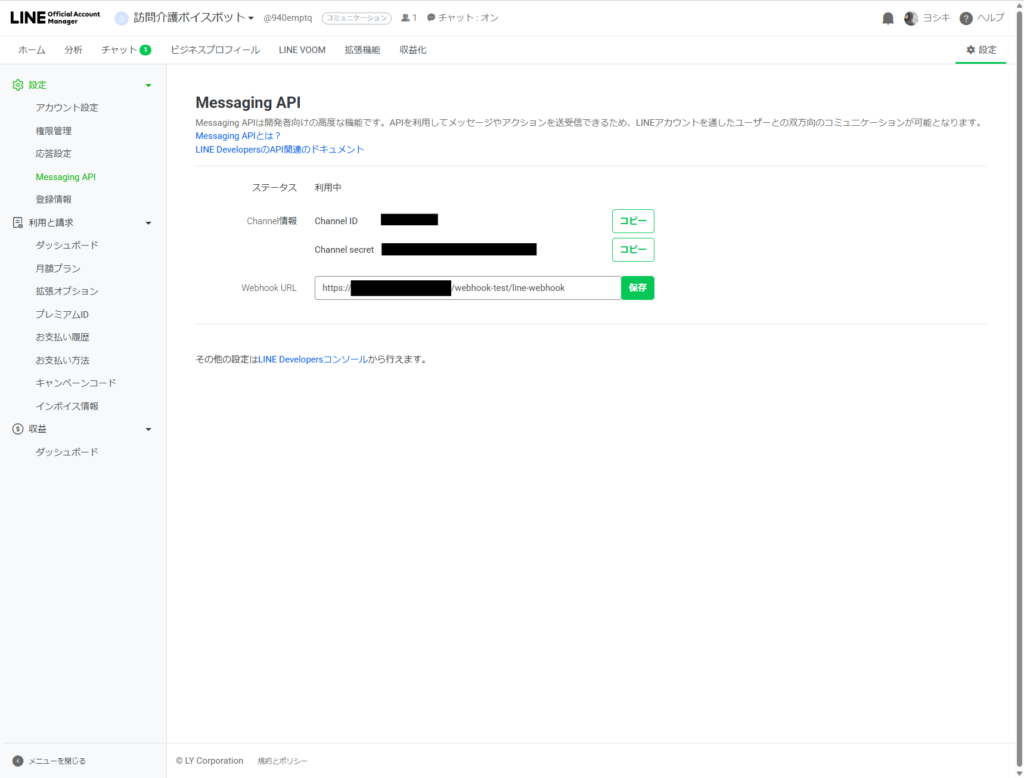
これでChannel IDとChannel Secretが発行されますが、Channel Access Tokenは別途LINE Developers Console側で発行する必要があります。Developers Consoleの該当チャネル→Messaging APIタブ→最下部の「Channel access token (long-lived)」で「Issue」ボタンを押すと、長い英数字のトークンが生成されます。
ElevenLabsはStarterプラン以上が事実上必須
ElevenLabsは無料プランでもAPIキーは取得できますが、実際にAPIを叩くと「Unusual activity detected. Free Tier usage disabled」というエラーで弾かれることが多いです。
これはn8nをRailwayなどクラウドサービスでホストしている場合、リクエスト元IPがデータセンターIPとして識別され、ElevenLabsのabuse detectorが発動するためです。
{
"detail": {
"status": "detected_unusual_activity",
"message": "Unusual activity detected. Free Tier usage disabled.
If you are using a proxy/VPN you might need to purchase a Paid Plan..."
}
}
最低でもStarter(月5ドル)プランへの加入が必要です。商用利用するなら、Voice Cloningが使えるCreator(月22ドル)が現実的な選択肢になります。
Supabaseのテーブル設計
会話履歴とリスクイベントを保存するテーブルを作成しました。SQL Editorで以下を実行します。
-- 会話履歴
create table conversations (
id uuid primary key default gen_random_uuid(),
line_user_id text,
role text not null check (role in ('user', 'assistant')),
content text not null,
content_masked text,
audio_url text,
duration_ms integer,
created_at timestamptz default now()
);
create index idx_conversations_line_user
on conversations(line_user_id, created_at desc);
-- リスク検知ログ
create table risk_events (
id uuid primary key default gen_random_uuid(),
line_user_id text,
conversation_id uuid references conversations(id),
risk_level text check (risk_level in ('low', 'medium', 'high')),
risk_category text,
detected_keywords jsonb,
llm_classification jsonb,
created_at timestamptz default now()
);
detected_keywordsは最初text[]型で作っていましたが、n8nから配列を渡す際にPostgreSQLの配列リテラル形式({値1,値2})が必要でハマったため、後でjsonb型に変更しました。jsonb型ならn8n側でJSON.stringify()を使うだけでシンプルに扱えます。
Supabase Storageのバケット設定
LINEに音声メッセージを返すには、HTTPSでアクセス可能な公開URLが必要です。Supabase Storageにaudio-responsesバケットを作成し、Public設定にしました。
ポリシー設定で「全員が読み取り可能(SELECT)」と「サービスからのアップロード可能(INSERT)」の2つを追加します。
n8nのデプロイ
Railwayにn8nをデプロイしました。Railway Templatesに「n8n」がいくつかありますが、サードパーティ製で構成も様々なため、結局Empty ServiceからDocker imageでn8n公式を直接デプロイする方法を選びました。
# Image
n8nio/n8n:latest
# Variables
N8N_BASIC_AUTH_ACTIVE=true
N8N_BASIC_AUTH_USER=admin
N8N_BASIC_AUTH_PASSWORD=(強固なパスワード)
WEBHOOK_URL=https://(Railway発行ドメイン)/
GENERIC_TIMEZONE=Asia/Tokyo
N8N_DEFAULT_BINARY_DATA_MODE=filesystem
DB_TYPE=sqlite
# Volume
Mount Path: /home/node/.n8nN8N_DEFAULT_BINARY_DATA_MODE=filesystemは音声ファイルを扱う上で重要です。デフォルトのメモリモードだと、長い音声メッセージでn8nが落ちる可能性があります。
Volumeをマウントしておかないと、再デプロイのたびにワークフローが消えてしまうので、必ず設定します。
ワークフロー構築:4つのパートに分けて段階的に
実装は4つのパートに分けて、各段階で動作確認を挟みながら進めました。一気に全機能を作ると、エラーが起きた時にどこが原因か特定できなくなるためです。
各パートの所要時間の目安は、パート1が1時間、パート2が2時間、パート3が2時間、パート4が2時間程度。実働で1〜2日のプロジェクトです。
パート1:最小ループ(テキスト入出力のみ)
まずはLINEでテキストメッセージを送ったら、Claudeが応答テキストを返す最小ループを作ります。これが動けば、配線とCredentialの設定は正しいことが確認できます。
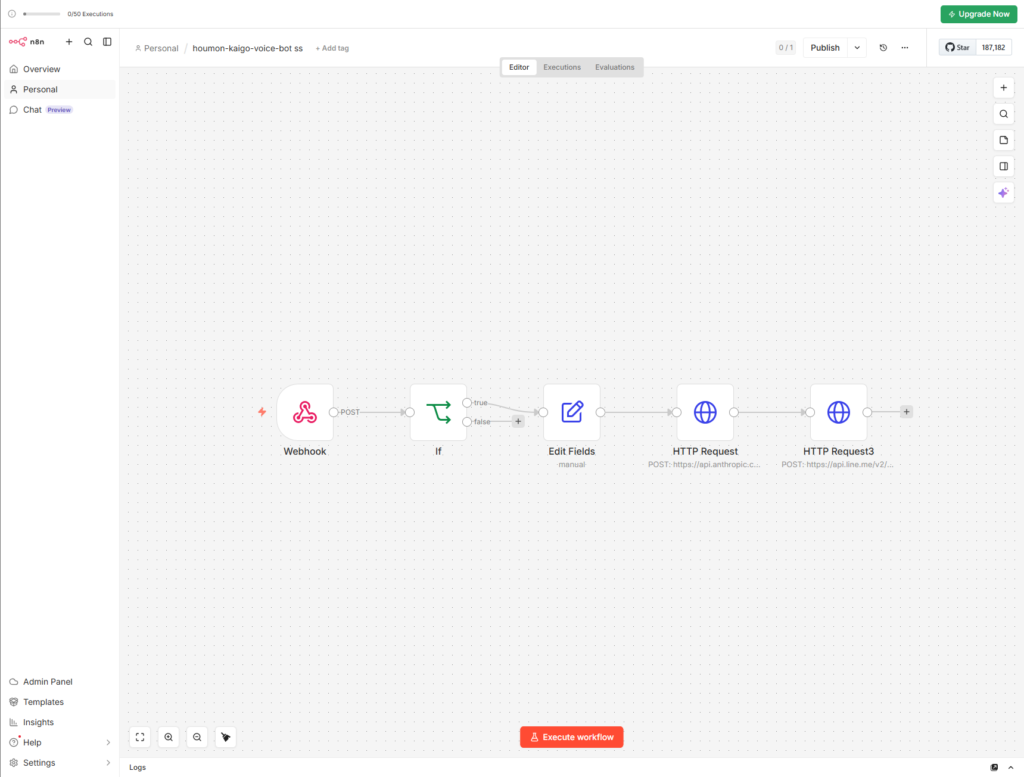
ノード1:Webhook(LINE受信)
「On webhook call」トリガーで開始します。
設定値は以下の通りです。
- HTTP Method:
POST - Path:
line-webhook - Authentication:
None - Respond:
Immediately - Response Code:
200
ここで表示されるTest URLを、LINE Developers ConsoleのWebhook URL欄に貼り付け、Webhookの利用をオンにします。
ノード2:IF(メッセージイベントの判定)
LINEのWebhookは様々なイベントを送ってくるので、メッセージイベントだけを処理します。
Value 1: {{ $json.body.events[0].type }}
Operation: equals
Value 2: messagetrueの分岐に進みます。
ノード3:Set(テキスト抽出)
LINEのリクエストボディから、後続の処理で使う情報を取り出します。
| Field Name | Value |
|---|---|
| user_text | ={{ $json.body.events[0].message.text }} |
| reply_token | ={{ $json.body.events[0].replyToken }} |
| line_user_id | ={{ $json.body.events[0].source.userId }} |
ノード4:HTTP Request(Claude API)
n8nのCustom Authで複数ヘッダーをまとめて登録するのが楽です。
Custom Authの設定(Settings → Credentials → Custom Auth):
{
"headers": {
"x-api-key": "sk-ant-api03-xxxxxxxxxxxxx",
"anthropic-version": "2023-06-01",
"Content-Type": "application/json"
}
}HTTP Requestノードの設定:
- Method:
POST - URL:
https://api.anthropic.com/v1/messages - Authentication: Generic Credential Type → Custom Auth → 上記Credential
- Send Body: ON
- Body Content Type:
JSON
JSON Body:
{
"model": "claude-sonnet-4-6",
"max_tokens": 400,
"system": "あなたは訪問介護事業所『○○ケアサービス』の問い合わせ対応AIです。やわらかく丁寧な敬語で、3文以内200字以内で応答してください。",
"messages": [
{
"role": "user",
"content": "={{ $json.user_text }}"
}
]
}ノード5:HTTP Request(LINE返信)
LINE Messaging APIにReplyリクエストを送ります。
Header AuthのCredentialを別途作成(Authorization: Bearer (Channel Access Token))。
設定値:
- Method:
POST - URL:
https://api.line.me/v2/bot/message/reply - Authentication: Header Auth → 上記Credential
- Send Headers: ON(
Content-Type: application/json) - Send Body: ON
- Body Content Type:
JSON
JSON Body:
{
"replyToken": "{{ $('Set').item.json.reply_token }}",
"messages": [
{
"type": "text",
"text": {{ JSON.stringify($json.content[0].text) }}
}
]
}ここで重要なのが、textフィールドの値を {{ JSON.stringify(...) }} で囲んでいることです。Claudeの応答に改行が含まれると、通常の文字列展開だとJSON Bodyがパースエラーになります。JSON.stringifyを使うことで、改行が\nにエスケープされ、JSONとして正しい形式になります。
このパートで動作確認できれば、認証とWebhookの設定は正しいということになります。最初のマイルストーンです。
パート2:音声対応の追加
テキスト分岐の隣に音声分岐を追加し、最後にMergeで合流させます。
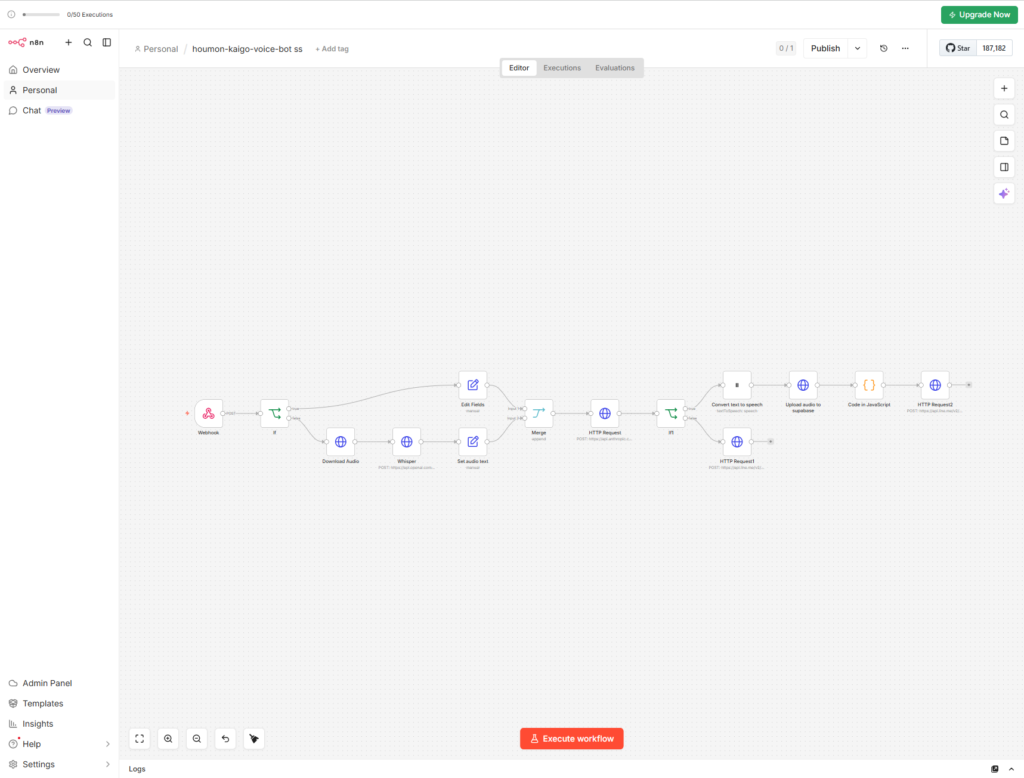
Switch(テキスト/音声判定)
ノード2のIFの次に、Switchノードを挿入します。LINEメッセージのtypeで分岐させます。
Rule 1: $json.body.events[0].message.type equals "text" → Output 0
Rule 2: $json.body.events[0].message.type equals "audio" → Output 1音声分岐:HTTP Request(音声ダウンロード)
LINEに保存されている音声ファイルをバイナリで取得します。
- Method:
GET - URL:
https://api-data.line.me/v2/bot/message/{{ $json.body.events[0].message.id }}/content - Authentication: LINE Messaging API(Header Auth)
- Response Format:
File - Put Output File in Field:
data
音声分岐:HTTP Request(Whisper API)
OpenAIのWhisper APIで音声を文字起こしします。
- Method:
POST - URL:
https://api.openai.com/v1/audio/transcriptions - Authentication: OpenAI Whisper(Header Auth:
Authorization: Bearer xxx) - Send Body: ON
- Body Content Type:
Form-Data Multipart
Body Parameters:
| Parameter Type | Name | Value |
|---|---|---|
| n8n Binary File | file | data |
| Form Data | model | whisper-1 |
| Form Data | language | ja |
language: jaを明示しないと、英語と認識される可能性があるので必須です。
音声分岐:Set(テキスト統合)
Whisperの結果を、テキスト分岐と同じデータ構造に揃えます。
| Field Name | Value |
|---|---|
| user_text | ={{ $json.text }} |
| reply_token | ={{ $('Webhook').item.json.body.events[0].replyToken }} |
| line_user_id | ={{ $('Webhook').item.json.body.events[0].source.userId }} |
| message_type | audio |
テキスト分岐側のSetノードにも、message_type: textフィールドを追加して構造を揃えます。
Merge(分岐の合流)
両分岐の出力を、Mergeノード(Mode: Append)で1つにまとめます。これで以降の処理は1本のフローになります。
Claude応答後の入出力経路の分岐
入力が音声だった場合のみ音声で返すため、Claude APIの後にIFノードを置きます。
Value 1: {{ $('Merge').item.json.message_type }}
Operation: equals
Value 2: audiotrueなら音声合成→音声返信、falseならテキスト返信。
音声合成:ElevenLabs
n8nの公式ElevenLabsノードを使うのが楽です。Credentialにはxi-api-keyを登録します。
- Resource:
Speech - Operation:
Text to Speech - Voice: 取得したVoice ID
- Text:
={{ $('Claude').item.json.content[0].text }} - Model:
Multilingual v2
ノードの出力はdataフィールドにバイナリデータとして格納されます。
Supabase Storageへのアップロード
n8nのSupabase組み込みノードはStorage操作に対応していないため、HTTP Requestで直接Storage APIを叩きます。
- Method:
POST - URL(Expressionモード):
https://(プロジェクトID).supabase.co/storage/v1/object/audio-responses/{{ $now.format('yyyyMMdd-HHmmss') }}-{{ $('Merge').item.json.line_user_id }}.mp3 - Send Headers: ON
Authorization: Bearer (service_role キー)Content-Type: audio/mpeg
- Send Body: ON
- Body Content Type:
Binary - Input Data Field Name:
data
URLが{{ ... }}を含む場合、必ずExpression モードに切り替える必要があります。Fixed モードのままだと{{ }}がそのまま文字列として送信され、Supabaseが「ファイル名に不正な文字」として400を返します。
音声長さの計算
LINEの音声メッセージ返信にduration(ミリ秒単位の音声長)が必須なため、Codeノードで概算します。ElevenLabsのレスポンスには長さ情報が含まれていないためです。
const text = $('Claude').item.json.content[0].text;
const charCount = text.length;
// 日本語1秒あたり約7文字として概算
const durationMs = Math.ceil((charCount / 7) * 1000);
// アップロード結果から公開URLを組み立て
const projectId = 'xxxxxxxxxxxxxxxx';
const fileName = $input.first().json.Key.replace('audio-responses/', '');
const audioUrl = `https://${projectId}.supabase.co/storage/v1/object/public/audio-responses/${fileName}`;
return [{
json: {
audio_url: audioUrl,
duration_ms: durationMs,
reply_token: $('Merge').item.json.reply_token
}
}];正確ではありませんが、LINE側は再生時間の目安として使うだけなので、概算で問題ありません。
LINE音声返信
最終的に、LINE Messaging APIに音声メッセージとして返します。
JSON Body:
{
"replyToken": "{{ $json.reply_token }}",
"messages": [
{
"type": "audio",
"originalContentUrl": "{{ $json.audio_url }}",
"duration": {{ $json.duration_ms }}
}
]
}originalContentUrlはHTTPSの公開URLである必要があります。Supabase Storageのバケットを Public 設定にしておかないと、ここで再生エラーになります。
パート3:会話履歴と個人情報マスキング
ここから業務AIとして実用に耐えるレベルの機能を追加します。MergeとClaude APIの間に、3つのノードを挿入します。
Mask PII(個人情報マスキング)
Codeノードで利用者氏名・電話番号・住所などをClaudeに渡す前にマスクします。
const item = $input.first().json;
const userText = item.user_text;
let masked = userText;
// 電話番号
masked = masked.replace(/0\d{1,4}[-\s]?\d{1,4}[-\s]?\d{4}/g, '[PHONE]');
// 郵便番号
masked = masked.replace(/〒?\d{3}-?\d{4}/g, '[ZIP]');
// よくある呼称(本番ではDBから動的生成)
const namePatterns = ['田中さん', '佐藤さん', '山田さん', '鈴木さん', '高橋さん'];
namePatterns.forEach((name, i) => {
masked = masked.replaceAll(name, `[USER_${i}]`);
});
return [{
json: {
...item,
masked_text: masked
}
}];完璧なマスキングは難しいので、MVP段階では電話番号・郵便番号・登録済み利用者名だけ確実に消す方針です。
Get History(会話履歴取得)
Supabaseノードで、conversationsテーブルから該当ユーザーの直近20件を取得します。
- Resource:
Row - Operation:
Get Many - Table:
conversations - Return All: OFF
- Limit:
20 - Filters:
- Field:
line_user_id - Comparison:
equals - Value(Expression):
{{ $('Mask PII').item.json.line_user_id }}
- Field:
Always Output Dataを有効にする必要があります。これを有効にしないと、履歴0件のときに後続のノードが実行されません。ただし、有効にすると履歴0件でも空オブジェクト{}が後続に渡されるため、次のCodeノードで除外処理が必要になります。
Build Messages(messages配列の構築)
Codeノードで、過去履歴と現在のメッセージを統合し、Claude APIに渡すmessages配列を作ります。
const historyItems = $('Get History').all();
// 空オブジェクト(Always Output Dataで生成されるもの)を除外
const validHistory = historyItems
.filter(item =>
item.json &&
item.json.role &&
(item.json.content || item.json.content_masked)
)
.map(item => ({
role: item.json.role,
content: item.json.content_masked || item.json.content,
created_at: item.json.created_at
}))
.sort((a, b) => new Date(a.created_at) - new Date(b.created_at));
const messages = validHistory.map(h => ({
role: h.role,
content: h.content
}));
messages.push({
role: 'user',
content: $('Mask PII').first().json.masked_text
});
return [{
json: {
...$('Mask PII').first().json,
messages: messages
}
}];filterで以下の3条件すべてを満たすアイテムだけを残しています。
item.jsonが存在するitem.json.roleが存在する(user または assistant)item.json.contentまたはitem.json.content_maskedが存在する
これで Always Output Data によって生成された空オブジェクト {} が除外され、最終的な messages 配列には valid なメッセージだけが残ります。
Claude APIノードの修正
パート1で作ったClaude APIノードのJSON Bodyを、履歴対応版に変更します。
{
"model": "claude-sonnet-4-6",
"max_tokens": 400,
"system": "あなたは訪問介護事業所『○○ケアサービス』の問い合わせ対応AIです。利用者やそのご家族からのLINEでの問い合わせに、やわらかく丁寧な敬語で応答します。訪問予定の確認、持ち物、駐車場の場所など定型的な問い合わせには簡潔に答えてください。訪問時間の変更・キャンセル依頼は『サービス提供責任者から折り返しご連絡します』と返してください。体調や症状に関する相談、薬の質問は『担当のケアマネジャーに確認してご連絡しますね』と返してください。1回の応答は3文以内、200字以内にまとめてください。",
"messages": ={{ JSON.stringify($json.messages) }}
}messagesフィールドの書き方が重要です。={{ JSON.stringify($json.messages) }} の形式で、外側のダブルクォートを付けないこと、JSON.stringifyを使うことの2点がポイントです。
これを "messages": "={{ $json.messages }}" のように書くと、配列が文字列化されてしまい「Input should be a valid array」エラーになります。
会話履歴の保存
LINE返信ノードの後に、Supabase Insertノードを2つ並べます。ユーザー発言とAI応答の両方を保存します。
ユーザー発言の保存:
| Column | Mode | Value |
|---|---|---|
| line_user_id | Expression | {{ $('Mask PII').item.json.line_user_id }} |
| role | Fixed | user |
| content | Expression | {{ $('Mask PII').item.json.user_text }} |
| content_masked | Expression | {{ $('Mask PII').item.json.masked_text }} |
AI応答の保存:
| Column | Mode | Value |
|---|---|---|
| line_user_id | Expression | {{ $('Mask PII').item.json.line_user_id }} |
| role | Fixed | assistant |
| content | Expression | {{ $('Claude').item.json.content[0].text }} |
ここで重要なのが、Value欄のExpression モードへの切り替えです。Fixed モードのまま ={{ ... }} を入れていると、文字列リテラルとしてそのまま保存されてしまい、データベースに =明日の予定... のように = が混入します。
パート4:リスク検知とエスカレーション
最後に、訪問介護AIで最も重要なリスク検知レイヤーを追加します。Mask PIIとGet Historyの間に、検知レイヤーを挿入します。
Risk Keywords(一段目:キーワード検知)
Codeノードで、軽量で高速なキーワード辞書による判定を行います。
const item = $input.first().json;
const text = item.masked_text;
const riskKeywords = {
emergency: ['倒れた', '息してない', '意識がない', '救急車', '心臓が', '呼吸が', 'けいれん', '出血', '痙攣'],
self_harm: ['死にたい', '消えたい', '殺して', '自殺', '飛び降り', '首吊り'],
distress: ['もう無理', '生きてる意味', 'いなくなりたい', 'つらい', '助けて']
};
let detectedLevel = 'low';
let detectedCategory = null;
let detectedKeywords = [];
for (const [category, keywords] of Object.entries(riskKeywords)) {
for (const kw of keywords) {
if (text.includes(kw)) {
detectedKeywords.push(kw);
if (category === 'emergency' || category === 'self_harm') {
detectedLevel = 'high';
detectedCategory = category;
} else if (category === 'distress' && detectedLevel === 'low') {
detectedLevel = 'medium';
detectedCategory = category;
}
}
}
}
return [{
json: {
...item,
risk_level_keyword: detectedLevel,
risk_category_keyword: detectedCategory,
detected_keywords: detectedKeywords
}
}];Risk LLM(二段目:Claude Haikuによる文脈分類)
キーワードでは検知できない曖昧な表現を、軽量LLMで分類します。
HTTP Requestノードで、Claude Haikuを呼び出します。
{
"model": "claude-haiku-4-5-20251001",
"max_tokens": 200,
"system": "あなたは介護事業所の問い合わせメッセージを分類するシステムです。以下のメッセージを分析し、JSONで応答してください。分類カテゴリは emergency(救急対応が必要)、self_harm(自傷・自殺リスクあり)、distress(強い精神的苦痛)、medical(医療判断を要する相談)、normal(通常の問い合わせ)の5つです。必ず以下のJSON形式のみで応答してください:{\"category\":\"...\",\"confidence\":0.0-1.0,\"reason\":\"...\"}",
"messages": [
{"role": "user", "content": {{ JSON.stringify($json.masked_text) }}}
]
}二段構えにすることで、コストとカバレッジのバランスを取っています。キーワードだけだと「もう疲れた」のような曖昧表現を取りこぼしますが、LLMだけだと毎回数百ms〜のレスポンスタイムが乗るため、まずキーワードで明確なものを高速処理し、グレーゾーンだけLLMに渡す設計です。
Risk Final(総合判定)
CodeノードでキーワードとLLMの判定を統合します。
const item = $input.first().json;
const previous = $('Risk Keywords').first().json;
let llmResult = { category: 'normal', confidence: 0 };
try {
const responseText = item.content[0].text;
llmResult = JSON.parse(responseText);
} catch (e) {
// JSON parseに失敗した場合はnormalとして扱う
}
const isHighRisk =
previous.risk_level_keyword === 'high' ||
['emergency', 'self_harm'].includes(llmResult.category);
const isMediumRisk =
previous.risk_level_keyword === 'medium' ||
['distress', 'medical'].includes(llmResult.category);
const finalLevel = isHighRisk ? 'high' : (isMediumRisk ? 'medium' : 'low');
return [{
json: {
...previous,
final_risk_level: finalLevel,
final_risk_category: llmResult.category !== 'normal' ? llmResult.category : previous.risk_category_keyword,
llm_classification: llmResult
}
}];Risk Switch(リスクレベル分岐)
Switchノードでリスクレベルにより3分岐します。
Rule 1: $json.final_risk_level equals "high" → Output 0(エスカレーション)
Rule 2: $json.final_risk_level equals "medium" → Output 1(限定応答 = 当面はlowと同じ)
Rule 3: $json.final_risk_level equals "low" → Output 2(通常応答)Output 1とOutput 2はどちらも既存のGet Historyノードに接続。最初はmediumとlowを同じ動作にし、運用しながら絞っていきます。
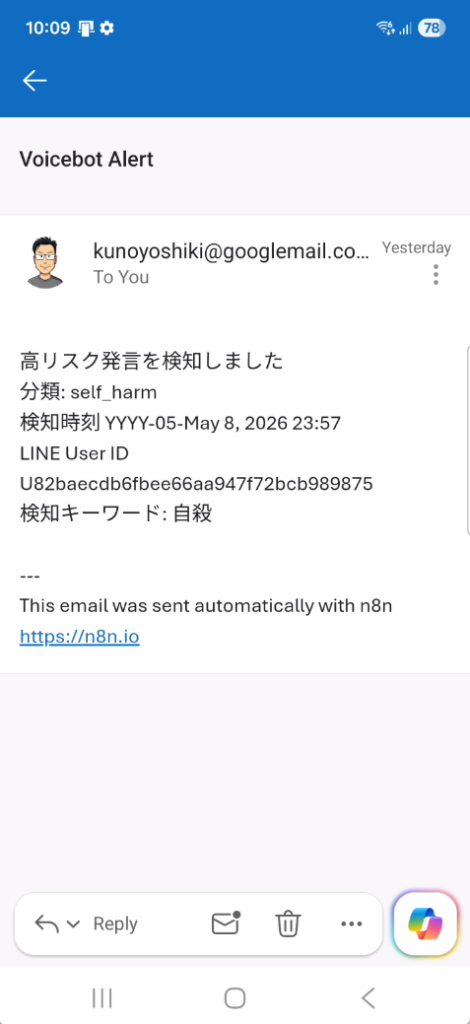
Notify Gmail(Gmail通知)
高リスク分岐の最初のノードです。設定したGmailアカウント宛にEメールを送信します。
高リスク発言を検知しました
分類: {{ $json.final_risk_category }}
検知時刻 {{ $now.format('YYYY-MM-DD HH:mm') }}
LINE User ID {{ $json.line_user_id }}
検知キーワード: {{ $json.detected_keywords.join(', ') }}Build Risk Reply(定型応答テキスト生成)
Codeノードで、リスクカテゴリに応じた定型テキストを生成します。
const item = $input.first().json;
const previous = $('Risk Final').first().json;
const category = previous.final_risk_category;
let replyText = '';
if (category === 'emergency') {
replyText = `お話くださってありがとうございます。
担当者にすぐ連絡しています。
緊急の場合は救急車(119)をお呼びください。`;
} else if (category === 'self_harm') {
replyText = `お話くださってありがとうございます。
担当のケアマネジャーがすぐにご連絡します。
今すぐ話を聞いてほしいときは、
よりそいホットライン(0120-279-338)が24時間つながります。
いのちの電話(0570-783-556)もご利用いただけます。`;
} else {
replyText = `お話くださってありがとうございます。
担当者から折り返しご連絡いたします。`;
}
return [{
json: {
reply_text: replyText,
reply_token: previous.reply_token,
...previous
}
}];Reply Risk Text(LINE固定テキスト返信)
HTTP Requestノードで、固定テンプレを返します。この分岐では音声合成は使いません。テキストのみで返します。合成音声で励ますような応答をしてしまうと、後の説明責任が重くなる倫理的判断によるものです。
{
"replyToken": "{{ $json.reply_token }}",
"messages": [
{
"type": "text",
"text": {{ JSON.stringify($json.reply_text) }}
}
]
}Save Risk Event(リスクイベント記録)
Supabase Insertノードで、risk_eventsテーブルに記録します。
| Column | Mode | Value |
|---|---|---|
| line_user_id | Expression | {{ $json.line_user_id }} |
| risk_level | Expression | {{ $json.final_risk_level }} |
| risk_category | Expression | {{ $json.final_risk_category }} |
| detected_keywords | Expression | {{ JSON.stringify($json.detected_keywords) }} |
| llm_classification | Expression | {{ JSON.stringify($json.llm_classification) }} |
detected_keywordsカラムはjsonb型に変更しておくのがおすすめです。text[]型のままだとPostgreSQLが要求する配列リテラル形式({値1,値2})でしか受け付けず、n8nから渡しにくくなります。
二段階の検知ロジック
このワークフローのリスク検知は二段階になっています。
一段目:キーワードマッチ
軽量で高速なキーワード辞書での判定です。
const riskKeywords = {
emergency: ['倒れた', '息してない', '意識がない', '救急車', '心臓が', '呼吸が'],
self_harm: ['死にたい', '消えたい', '殺して', '自殺'],
distress: ['もう無理', '生きてる意味', 'いなくなりたい', 'つらい']
};二段目:Claude Haikuによる文脈分類
キーワードでは検知できない曖昧な表現を、軽量LLMで分類します。
{
"model": "claude-haiku-4-5-20251001",
"max_tokens": 200,
"system": "介護事業所の問い合わせメッセージを分類するシステムです。emergency/self_harm/distress/medical/normalの5カテゴリで分類し、JSON形式で応答してください。",
"messages": [ {"role": "user", "content": "(マスキング済みメッセージ)"} ]
}二段構えにすることで、コストとカバレッジのバランスを取っています。キーワードだけだと「もう疲れた」のような曖昧表現を取りこぼしますが、LLMだけだと毎回数百ms〜のレスポンスタイムが乗るため、まずキーワードで明確なものを高速処理し、グレーゾーンだけLLMに渡す設計です。
エスカレーションフロー
検知ロジックがメッセージの内容を高リスクと判定したら、責任者のGmailアカウントにEメールを送信し、利用者には定型テキストを返します。
このとき重要なのは、AIの自由応答を絶対に使わないことです。テンプレートで固定したテキストのみを返します。
お話くださってありがとうございます。
担当のケアマネジャーがすぐにご連絡します。
今すぐ話を聞いてほしいときは、
よりそいホットライン(0120-279-338)が24時間つながります。
いのちの電話(0570-783-556)もご利用いただけます。
合成音声で励ますような応答をしてしまうと、後の説明責任が重くなる倫理的判断によるものです。
実装中にハマったポイントまとめ
実装記録として、つまずいた点を整理しておきます。同じ構成を作る方の時間節約になればと思います。
- LINE連携の管理画面の分かりにくさ
-
LINE連携の実装は今回で3回目ですが、毎回ハマります。LINE Official Account ManagerとLINE Developers Consoleに管理画面が分かれており、設定項目がどちらにあるか一見わかりにくい構造です。
たとえば、Messaging APIの有効化はOfficial Account Manager側で行いますが、Channel Access Tokenの発行はDevelopers Console側です。
- JSON Body内の改行エスケープ
-
Claudeの応答に改行が含まれると、LINE返信のJSON Bodyがパースエラーになる。
{{ JSON.stringify($json.content[0].text) }}を使う。 - 配列・オブジェクトのexpression評価
-
n8nのValue欄をExpressionモードに切り替えないと、
={{ ... }}が文字列リテラルとして保存されてしまう。データベースに=明日の予定...のように=が混入していたら要注意。
当社にとって初めての規模感
今回のプロジェクトは、当社がこれまで構築してきたn8nワークフローと比べて、明らかに一段大きい規模です。具体的に「初めての経験」だった点を整理しておきます。
ノードが10個以上のワークフロー構築
これまでは5〜7個のノードで完結する小規模なワークフローばかりでした。今回は最終的に20個近いノードを持つ構成になり、ワークフロー画面のスクロールが必要なほどの規模になりました。ノードが増えると、データの流れを頭の中で追跡するのが難しくなるため、ノード名を「Mask PII」「Get History」「Build Messages」のように機能を表す名前に統一することの重要性を実感しました。
IF・Switch・Mergeなど条件分岐の本格活用
従来は単純な直線的フローが中心でしたが、今回はテキスト/音声の分岐、リスクレベルによる3分岐、入出力経路の合流など、条件分岐とMergeを多用しました。条件分岐後にMergeで合流させる際の参照ノードの指定方法、Always Output Dataを有効にする必要があるケースなど、実装してみて初めて気づく挙動が多々ありました。
これらは個別には経験があったものの、1つのプロジェクトに全てを組み合わせるのは初めてで、設計レビュー・実装・テストの各フェーズで学びが多かったです。
今回のプロジェクトから得た気づき
実装を通して気づいた技術的・サービス的なポイントを記録しておきます。
月額コストの実測
訪問介護事業所1拠点・利用者30名・月500メッセージ程度の利用で、各サービスの実測コストは以下でした。
| サービス | 実額 |
|---|---|
| Railway(n8n) | 5ドル |
| Anthropic Claude(Sonnet+Haiku) | 18ドル |
| OpenAI Whisper | 4ドル |
| ElevenLabs(Starter) | 5ドル |
| Supabase | 0ドル |
| 合計 | 32ドル(約4,800円) |
商用のAI電話ボットが月額数万円〜数十万円する中で、この経済性は中小事業者にとって大きな魅力です。
まとめと次のステップ
n8n + Whisper + Claude + ElevenLabsの組み合わせで、訪問介護向けの音声対応LINEアシスタントが構築できました。実装期間は実働3日程度です。
次のステップとして、以下を検討しています。
- 誤検知・見逃しのデータを蓄積してリスクキーワード辞書とシステムプロンプトをチューニング
- 個別の利用者ごとに会話文脈をカスタマイズ(既往症や担当者情報をシステムプロンプトに動的注入)
- Twilio + OpenAI Realtime APIでの本物のリアルタイム電話AI(高齢者本人が直接電話できる仕組み)
なお、本記事で扱った「リスク検知レイヤー」の設計思想は、訪問介護以外の業種でも応用が効きます。クリニック・士業・不動産・建設業など、AIに任せていい応答とAIに任せてはいけない応答の境界がある業種では、同じアーキテクチャがそのまま使えます。








コメント