

中小企業向けの業務システムを開発していると、AIエージェントを実装方法が複数あって迷うことがあります。n8nのようなGUIワークフローツール、LangGraphのようなコードフレームワーク、そしてLLMプロバイダーの公式SDKを直接使う方法。
本記事では、3つ目の選択肢であるAnthropic SDKを直接使ったAIエージェント実装を試してみました。題材はチャットとメモリだけの最小構成。
実装した結果見えてきたのは、最小構成ではフレームワークを使ってもSDK直叩きでも、コード量や複雑性にほとんど差が出ないという事実です。本記事ではこの体験を踏まえて、n8n・LangGraph・SDK直叩きの使い分けの境界線を整理していきます。
なお、本記事は「n8nのAIエージェントノードをLangGraphで書き直してみた」の続編でもあります。LangGraph版の実装が気になる方はあわせてご覧ください。

この記事で作るもの
n8nで言うところの、
Chat Trigger → AI Agent (Claude) → Simple Memory
という3つのノードに相当する処理を、Anthropic SDKだけで実装します。使うライブラリは anthropic(公式SDK)と python-dotenv のみ。LangChain系のライブラリは一切使いません。
完成形は、ターミナル上で対話ができ、複数ターンにわたって会話履歴が保持される、シンプルなチャットボットです。
なぜSDK直叩きという選択肢を試すのか
業務システム開発の現場では、フレームワークを選ぶこと自体が技術判断のひとつです。
LangChainやLangGraphのようなフレームワークは便利ですが、依存ライブラリの追加・バージョン互換性の管理・フレームワーク独自の概念学習といったコストが必ず発生します。プロジェクトが小規模なら、フレームワークの恩恵よりもこれらのコストの方が大きくなる場合があります。
SDKを直接叩く目的は3つあります。
- フレームワークが内部でやっている処理を可視化する
- 依存ライブラリを最小化したときに保守性がどう変わるかを体感する
- 自分たちが本当にフレームワークを必要としているかを判断する材料を持つ
特に最後の点が重要です。中小企業向けの業務システムを設計する立場としては、お客様の運用フェーズ・社内のIT人材・予算規模に応じて、「n8n 」「LangGraphか」「SDK直叩き」「あるいは別の選択肢」を判断できる必要があります。そのためには、それぞれの実装を実際に書いて感触を確かめておくのが一番確実です。
環境構築
検証環境はWindows 11、Python 3.12、VS Codeです。Macでもコマンドを少し読み替えれば同じように動作します。
プロジェクトフォルダと仮想環境
mkdir anthropic-sdk-chat-minimum
cd anthropic-sdk-chat-minimum
python -m venv .venv
.venv\Scripts\activateMac/Linuxなら source .venv/bin/activate で有効化します。
パッケージのインストール
必要なパッケージは2つだけです。
pip install anthropic python-dotenv| パッケージ | 役割 |
|---|---|
anthropic | Claude APIを直接呼ぶための公式SDK |
python-dotenv | .env ファイルからAPIキーを読み込む |
LangGraphやLangChainを使う場合と比べて、依存ライブラリが2つ減ることになります。この差は本番運用での保守性に直結します。依存が少ない=壊れにくい、アップデートが楽、というメリットがあります。
APIキーの設定
プロジェクト直下に .env ファイルを作成します。
ANTHROPIC_API_KEY=sk-ant-api03-xxxxxxxxxxxxxAPIキーはAnthropic Console(https://console.anthropic.com/)で発行できます。
合わせて、APIキーの流出を防ぐため .gitignore も作成しておきます。
.env
.venv/
__pycache__/
*.pycこれを忘れるとGit公開時にAPIキーが流出するので、必須です。
実装:SDKで最小構成のチャットボットを作る
それではコードを書いていきます。
プロジェクト直下に chat.py を作成します。完成形のコード全体は以下のとおりです。
from dotenv import load_dotenv
import anthropic
load_dotenv()
client = anthropic.Anthropic()
# thread_idごとにメッセージリストを保持する辞書
conversations = {} # 例:{"session-1": [...messages...]}
def get_messages(thread_id):
if thread_id not in conversations:
conversations[thread_id] = []
return conversations[thread_id]
def add_message(thread_id, role, content):
messages = get_messages(thread_id)
messages.append({"role": role, "content": content})
def call_claude(messages):
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=messages,
)
return response.content[0].text
def chat_turn(thread_id, user_input):
# ユーザー発言を履歴に追加
add_message(thread_id, "user", user_input)
# 履歴全体をClaudeに渡して応答取得
messages = get_messages(thread_id)
assistant_response = call_claude(messages)
# 応答を履歴に追加
add_message(thread_id, "assistant", assistant_response)
return assistant_response
thread_id = "session-1"
print("チャットを開始します。終了するには 'quit' または 'exit' と入力してください。\n")
while True:
user_input = input("あなた: ")
if user_input.lower() in ["quit", "exit"]:
print("チャットを終了します。")
break
response = chat_turn(thread_id, user_input)
print(f"Claude: {response}\n")
約45行です。コードの中身を、要素ごとに見ていきます。
クライアントの初期化
client = anthropic.Anthropic()load_dotenv() で読み込んだ ANTHROPIC_API_KEY を、anthropic.Anthropic() が環境変数から自動的に取得します。
モデル名や max_tokens などのパラメータは、クライアント作成時ではなく呼び出しごとに指定する設計になっています。LangChain系の ChatAnthropic(model=..., max_tokens=...) のような事前バインドではなく、毎回必要な情報を渡すスタイルです。
メモリの自作(n8nのSimple Memoryに相当する部分)
ここが今回の実装のポイントです。
conversations = {}
def get_messages(thread_id):
if thread_id not in conversations:
conversations[thread_id] = []
return conversations[thread_id]
def add_message(thread_id, role, content):
messages = get_messages(thread_id)
messages.append({"role": role, "content": content})この部分がn8nのSimple Memoryノード、あるいはLangGraphのMemorySaver(Checkpointer)に相当する処理です。
実装内容はシンプルです。conversations という辞書を用意し、thread_id をキーにしてメッセージリストを保持しているだけです。新しいメッセージが来たら、その thread_id に紐づくリストに追加していきます。
n8nのSimple MemoryノードもLangGraphのMemorySaverも、本質的にやっていることはこれと同じです。ただし、それぞれフレームワークの設計に応じて追加機能(ウィンドウサイズ制御、State全体のスナップショット保存、永続化バックエンドの切り替えなど)が付いています。
今回のように「メッセージリストだけ持てればいい」ならば、自前で実装でも全く問題ありません。
LLM呼び出し関数
def call_claude(messages):
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=messages,
)
return response.content[0].textここがLLMを呼び出す部分です。
注目していただきたいのは messages 引数の形式です。SDK直叩きでは、メッセージは辞書形式 {"role": "user", "content": "..."} で渡します。これはAnthropic APIの公式仕様そのままです。LangChain版のように HumanMessage クラスを使う必要はありません。
応答の取り出しも response.content[0].text という素直な構造です。content がリストになっているのは、将来的に画像入力やツール使用結果が混ざる可能性を考慮した設計です。今回はテキスト応答だけなので [0] で最初の要素を取り出しています。
1ターン処理の全体像
def chat_turn(thread_id, user_input):
add_message(thread_id, "user", user_input)
messages = get_messages(thread_id)
assistant_response = call_claude(messages)
add_message(thread_id, "assistant", assistant_response)
return assistant_responseここがLangGraph版で言うところの「グラフを実行する」処理に相当します。
処理の流れは、ユーザー発言を履歴に追加 → 履歴全体をClaudeに渡す → 応答を取得 → 応答を履歴に追加 → 応答を呼び出し元に返す、という5ステップです。
LangGraph版ではこれらが全て graph.invoke(...) の中で自動的に行われていました。SDK直叩きでは1つ1つの手順を自分で書く必要があります。ただし、書いている処理の中身そのものは変わりません。フレームワークが隠していた処理が見えているだけです。
対話ループ
thread_id = "session-1"
while True:
user_input = input("あなた: ")
if user_input.lower() in ["quit", "exit"]:
break
response = chat_turn(thread_id, user_input)
print(f"Claude: {response}\n")thread_id を固定値で持ち回しているので、起動中は同一の会話として扱われます。複数のユーザーや複数の会話セッションを扱うときは、ここを動的に切り替えることになります。
動かして試してみる
ターミナルで実行します。
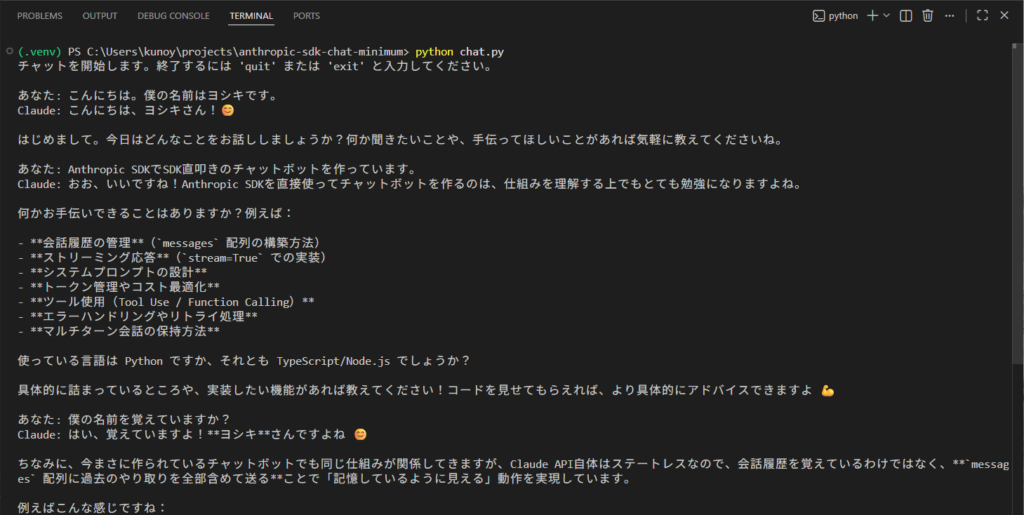
python chat.py3ターン試してみます。
あなた: こんにちは。僕の名前はヨシキです。
Claude: こんにちは、ヨシキさん!😊 はじめまして。今日はどんなことをお話ししましょうか?(以下省略)
あなた: Anthropic SDKでSDK直叩きのチャットボットを作っています。
Claude: お、いいですね!Anthropic SDKを直接使ってチャットボットを作るのは、仕組みを理解する上でもとても勉強になりますよね。何かお手伝いできることはありますか?(以下省略)
あなた: 僕の名前を覚えていますか?
Claude: はい、ですね。
3ターン目で名前を覚えています。自作メモリが正しく機能していることが確認できます。
n8n・LangGraph・SDK直叩きを比較する
ここまで動いたところで、n8n・LangGraph・SDK直叩き、それぞれのパターンを整理しておきます。
| 項目 | n8n | LangGraph版 | SDK直叩き版 |
|---|---|---|---|
| 実装形態 | GUIノード接続 | Pythonコード | Pythonコード |
| 必要な技術スキル | 低(GUI操作) | 中(Python + フレームワーク学習) | 中(Python + API仕様理解) |
| コード行数 | 0行 | 約50行 | 約45行 |
| メッセージ管理 | Simple Memoryノード | MemorySaver | 辞書とgetter/setterを自前実装 |
| 透明性 | 低(ノード内部はブラックボックス) | 中(フレームワークが一部隠す) | 高(全ての処理が見える) |
| カスタマイズ性 | 低(用意された機能の範囲内) | 中(フレームワークの作法に従う) | 高(何でも書ける) |
| 学習コスト | 低 | 高(独自概念が多い) | 中(Python標準知識) |
正直な感想として、LangGraph版とSDK直叩き版の差はそれほど大きくないです。行数も依存ライブラリ数もほぼ同じで、書く処理の中身もあまり変わりません。「LangGraphが裏でやっていたこと」を書くつもりが、書く対象そのものがそもそも少なかった、というのが実際のところです。
n8n版は「ノードを3つ繋ぐだけ」で同じことが実現できるので、こちらの方が圧倒的に手軽です。
LangGraphの真価が出る場面
視点を変えてみましょう。LangGraphはどういった場面で真価を発揮するのか?
LangGraphが本来活躍するのは、以下のような複雑性を持つワークフローです。
複数ノードの条件分岐がある
「ユーザー入力 → 意図判定 → 適切なツール選択 → ツール実行 → 結果統合」のような分岐を含むワークフローでは、グラフ構造で明示的に流れを定義できるLangGraphが圧倒的に読みやすくなります。SDK直叩きで同じことをやろうとすると、if 文と関数呼び出しが入り組んで、コード全体の見通しが急に悪化します。
状態管理が複雑
メッセージ履歴だけでなく、ユーザー情報、検索結果、ツール実行ログなど、複数のフィールドを持ち回す必要があるとき。LangGraphのStateは型付きの構造を持てるため、各ノードが「どのフィールドを読み、どこを更新するか」を明示的に書けます。SDK直叩きで同じことをやろうとすると、自前で巨大な辞書を管理することになります。
ループや再帰が必要
エージェントが「タスクが完了するまでツール呼び出しを繰り返す」ような実装は、LangGraphの条件分岐エッジで自然に書けます。SDK直叩きでは while ループと終了条件判定、エラー時の継続/中断判断を自分で組み立てる必要があります。
人によるインタラクションを挟む
「ある段階で人間のレビューを待ち、承認されたら次に進む」というワークフローは、LangGraphのCheckpointer + interrupt機能で実装できます。SDK直叩きで同じ機能を作ろうとすると、状態の永続化、再開ロジック、UI連携などを全て自前で書くことになり、相当な実装量になります。
今回の「チャット + メモリ」は、これらのいずれにも該当しません。ノードは1つ、Stateは単純なメッセージリスト、ループも分岐も人間介入もありません。つまり、LangGraphが用意している機能のほとんどを使っていない状態です。これでは差が出ないのも当然でした。
SDK直叩きで見えてきたこと
ここまでの実装と比較を踏まえて、率直に感じたことを整理しておきます。
まとめ
本記事では、Anthropic SDKを直接使ったチャットボット実装を試してみました。
結果として見えてきたのは、「最小構成ではLangGraphとSDK直叩きにほとんど差が無く、フレームワークの真価は複雑な要件が出てから初めて現れる」という事実でした。これは技術選定の現場では当たり前のように語られることですが、実際に同じ要件を両方で書いてみることで、肌感覚として実感できました。
中小企業の業務システムを設計する立場としては、「とりあえずLangGraphを使う」でも「最初からSDK直叩きで頑張る」でもなく、要件の複雑性に応じて段階的にツールを選ぶのが正解だと思います。最初はn8n、複雑になったらLangGraph、さらに細かい制御が必要になったらSDK直叩きの部分実装を組み合わせる、という流れが現実的です。








コメント