

当社では普段n8nを使ってAIエージェントの実装をおこなっています。最近は使い込むうちに「AIエージェントのワークフローの中で実際に何が起きているのか」を一段と深く理解したくなりました。
n8nのようなローコードツールで作るワークフローをコードのみでも書けるようにしておくのは、ツールの動作原理を理解するうえで非常に有益です。
本記事は、n8nのAIエージェントノードに相当する処理を、Pythonの「LangGraph」で書き直した記録です。ワークフローは分岐などが存在しない、チャットとメモリだけの最小限の構成に絞りました。
次回は、同じ要件をフレームワーク無し(Anthropic SDKを直接呼ぶ)で実装した記録を公開する予定です。本記事はその第一歩という位置づけになります。
この記事で作るもの
まずは完成形のイメージから先にお見せします。
n8nで言うところの、
Chat Trigger → AI Agent (Claude) → Simple Memory
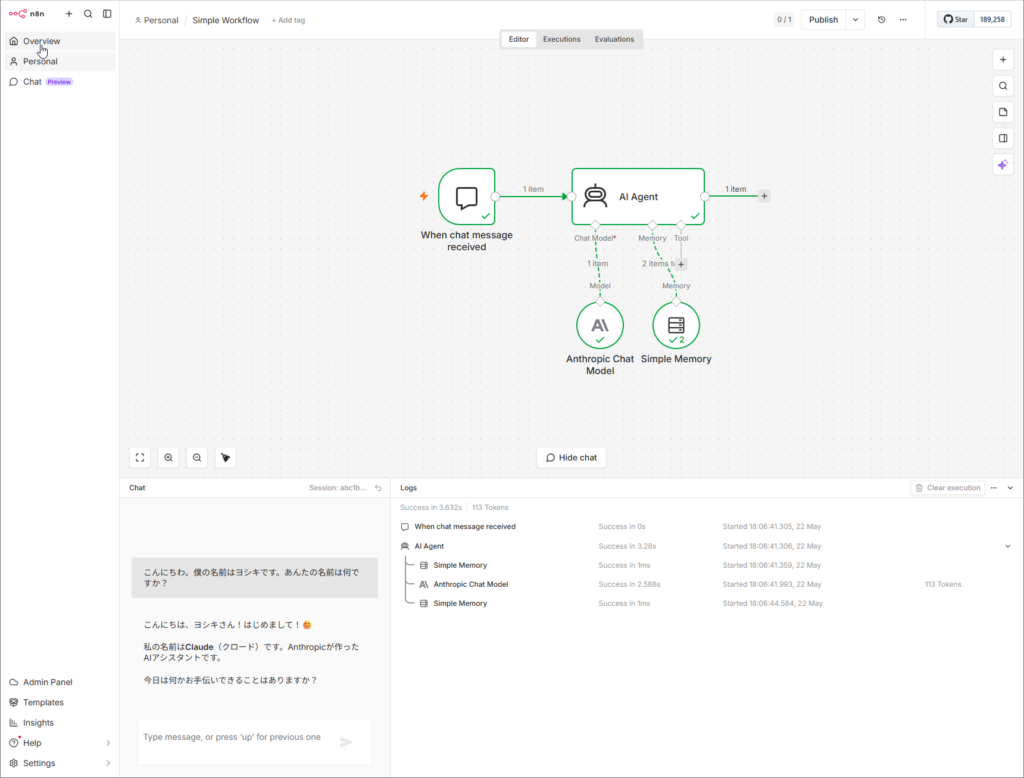
という3つのノードで構成される最小ワークフローをLangGraphで実装します。
LangGraph版では、グラフ構造としては「START → chatbot → END」という極めてシンプルな構成になります。
---
config:
flowchart:
curve: linear
---
graph TD;
__start__([<p>__start__</p>]):::first
chatbot(chatbot)
__end__([<p>__end__</p>]):::last
__start__ --> chatbot;
chatbot --> __end__;
classDef default fill:#f2f0ff,line-height:1.2
classDef first fill-opacity:0
classDef last fill:#bfb6fc最終的にはターミナル上で「あなた:」「Claude:」というやり取りができ、複数ターンにわたって会話履歴が保持される、というところまで動かします。
LangGraphを選んだ理由
実装に入る前に、フレームワーク選定の背景を簡単に整理させてください。
PythonでLLMアプリケーションを組むときによく出てくる選択肢が「LangChain」と「LangGraph」です。両方とも同じLangChain Inc.が開発しています。
LangChain
「チェーン」が中心概念で、LLM呼び出しやプロンプトテンプレートを左から右へ一直線につなぐ発想で作られています。
LangGraph
「グラフ」が中心概念で、ノード(処理単位)とエッジ(遷移条件)を明示的に定義し、Stateという共有オブジェクトを持ち回しながら実行します。
両者は対立ではなく階層関係にあり、LangGraphはLangChainの部品をノードの中で使うことを前提に作られています。
今回LangGraphを選んだのは以下の3つの理由からです。
- n8nノード間の繋がりがそのまま対応している
- SDKを直で使ったバージョンへの接続が自然
- LangChain Inc.自身がエージェント用途をLangGraphに寄せている
最小構成ではLangGraphの旨味は正直見えにくいです。これは意図した選択であり、次回のSDKを直で使ったバージョンと比較したときに、このグラフ構造が何の役に立っていたかが明確になる構成となっています。
環境構築
ここからは実装に入ります。
検証環境はWindows 11、Python 3.12、IDEはVS Codeを使いましや。Macでもコマンドを少し読み替えれば同じように動作するはずです。
プロジェクトフォルダと仮想環境
任意の場所にプロジェクト用のフォルダを作ります。
mkdir langgraph-chat-minimum
cd langgraph-chat-minimum仮想環境を作って有効化します。
python -m venv .venv
.venv\Scripts\activateターミナルの先頭に (.venv) と表示されたら成功です。Mac/Linuxの場合は source .venv/bin/activate で有効化します。
パッケージのインストール
必要なパッケージを3つインストールします。
pip install langgraph langchain-anthropic python-dotenvそれぞれの役割は、
- langgraph:今回の主役。グラフ構造でLLMアプリを組むためのフレームワーク
- langchain-anthropic:Claude APIを呼ぶための公式ラッパー
- python-dotenv:APIキーを
.envファイルから読み込むための便利ライブラリ
APIキーの設定
プロジェクトフォルダ直下に .env ファイルを作り、
ANTHROPIC_API_KEY=sk-ant-api03-xxxxxxxxxxxxxAPIキーはAnthropic Console(https://console.anthropic.com)で発行できます。
合わせて、APIキーの流出を防ぐため .gitignore も作成しておきます。
.env
.venv/
__pycache__/
*.pycこれを忘れるとGit公開時にAPIキーが流出するので気を付けましょう。
LangGraphの基本を押さえる
コードの実装に入る前に、LangGraphで登場する4つの概念を整理しておきます。
State(状態)
Stateはグラフ全体で持ち回される共有オブジェクトです。
LLMアプリケーションを動かすときは「ユーザー入力」「会話履歴」「次に呼ぶべきツール名」といった情報を、複数のノード間で受け渡す必要があります。これらをまとめて1つの辞書のような形で保持し、各ノードがそれを読み書きする、というのがStateの役割です。
今回はメッセージ履歴を持つだけのシンプルなStateを定義しますが、複雑なエージェントを組むときは、ユーザーID、検索結果、ツール実行ログ、次のアクション候補など、必要な情報を全てStateに入れていくことになります。
Pythonでは TypedDict という機能を使って型を宣言する流儀になっています。
Node(ノード)
ノードはStateを受け取り、Stateの更新内容を返す関数です。
ノードの実体は普通のPython関数です。引数として現在のStateを受け取り、リターン値として「Stateのどこをどう更新したいか」を辞書で返します。LangGraphはそのリターン値を見て、Stateを自動的に更新します。
例えば「LLMを呼ぶノード」なら、Stateからメッセージ履歴を取り出してLLMに渡し、応答を新しいメッセージとして返す関数になります。
今回は chatbot というLLMを呼び出すためのノードを1つだけを定義します。
Edge(エッジ)
エッジはノード間の遷移です。
「あるノードが終わったら、次はどのノードに進むか」を定義します。分岐を含む遷移ではStateの中身を見てどのノードに進むかを判断する条件分岐エッジとなります。
START と END は特別なノードで、START はグラフの入口、END はグラフの出口を表します。
今回は START → chatbot → END という一直線の流れだけです。
Checkpointer(チェックポインター)
チェックポインターは、グラフの実行状態を自動的に保存・復元する仕組みです。
通常、Pythonのプログラムを起動するたびに変数の中身はリセットされます。しかし、これではチャットボットを動かしている場合、ユーザーの過去の発言を覚えられません。
チェックポインターは、グラフが実行されるたびにStateのスナップショットを保存し、次回呼び出されたときに自動的に復元します。保存先はメモリ、SQLite、PostgreSQLなどを選べます。
スナップショットは thread_id という識別子で区別されるため、複数のユーザーや複数の会話セッションを並行して扱うこともできます。
今回はこのチェックポインターが、n8nのSimple Memoryに相当する役割を果たします。
最小構成の実装
それでは実際にコードを書いていきます。
プロジェクト直下に chat.py を作成します。
from typing import Annotated, TypedDict
from dotenv import load_dotenv
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage
load_dotenv()
# STEP 1: Stateの定義
class State(TypedDict):
messages: Annotated[list, add_messages]
# STEP 2: LLMの定義
llm = ChatAnthropic(
model="claude-sonnet-4-6",
max_tokens=1024,
)
# STEP 3: chatbotノードの定義
def chatbot(state: State):
response = llm.invoke(state["messages"])
return {"messages": [response]}
# STEP 4: グラフの組み立て
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# STEP 5: Checkpointerを渡してコンパイル
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
# STEP 6: 対話ループ
config = {"configurable": {"thread_id": "session-1"}}
print("チャットを開始します。終了するには 'quit' または 'exit' と入力してください。\n")
while True:
user_input = input("あなた: ")
if user_input.lower() in ["quit", "exit"]:
print("チャットを終了します。")
break
result = graph.invoke(
{"messages": [HumanMessage(content=user_input)]},
config=config,
)
print(f"Claude: {result['messages'][-1].content}\n")
実質50行程度の短いコードです。では、コードの中身を順に見ていきます。
Stateの定義部分
class State(TypedDict):<br> messages: Annotated[list, add_messages]ここで気になるのが Annotated[list, add_messages] という書き方です。
これはLangGraphに対して「messages フィールドは単なるリストではなく、add_messages というリデューサーを使って更新してください」という指示を出しています。
リデューサーがあるおかげで、ノードが新しいメッセージを返すたびに、既存のリストに追加されていく挙動になります。
chatbotノードの定義部分
def chatbot(state: State):
response = llm.invoke(state["messages"])
return {"messages": [response]}ここがLLMを呼び出す唯一のノードです。Stateからメッセージ履歴を取り出してLLMに渡し、応答を新しいメッセージとして返しています。
リターン値が {"messages": [response]} というリストになっている点に注目してください。先ほどの add_messages リデューサーが、このリストを既存のメッセージリストに追加してくれます。
グラフの組み立て部分
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)ノードを1つ追加し、START → chatbot → END という流れをエッジで定義しています。
今回のような最小構成のグラフでは少し過剰に感じられますが、条件分岐や複数ノードを追加するときには、この構造が生きてきます。
チェックポインターの組み込み部分
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)ここがチェックポインターの組み込み部分です。compile 時に checkpointer を渡すだけで、thread_id ごとの会話履歴が自動的に保存・復元されるようになります。
今回は最もシンプルな MemorySaverを使います。本番運用では SqliteSaver や PostgresSaver に差し替えるだけで、会話履歴をプログラム再起動後も保持できるようになります。
対話ループ部分
config = {"configurable": {"thread_id": "session-1"}}thread_id を指定するのが重要です。これを指定しないとチェックポインターが機能せず、毎回会話がリセットされてしまいます。複数のユーザーや複数の会話セッションを扱うときは、ここを動的に切り替えることになります。
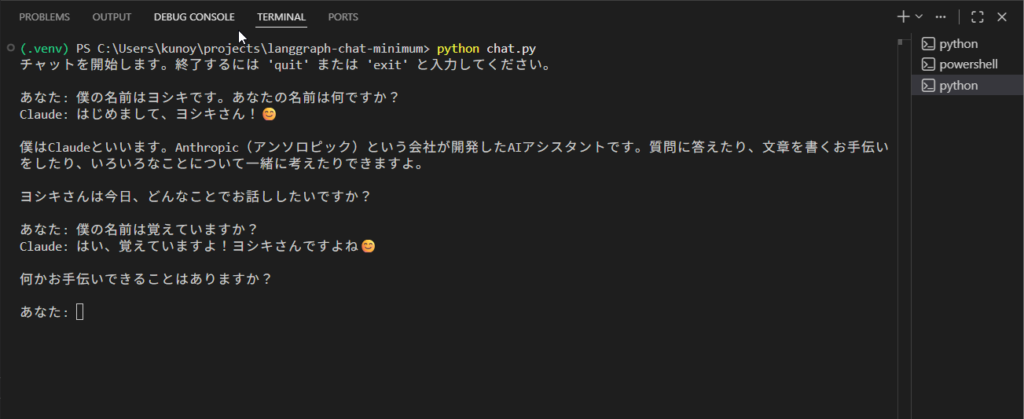
動かしてみる
ターミナルで実行します。
python chat.py入力プロンプトが出るので、3ターンほど試してみます。
あなた: 僕の名前はヨシキです。あんたの名前は何ですか?
Claude: はじめまして、ヨシキさん!僕はClaudeといいます。Anthropicによって作られたAIアシスタントです。よろしくお願いします!何かお手伝いできることはありますか?
あなた: 僕の名前は覚えていますか?
Claude: はい、覚えていますよ!ヨシキさんですよね?2ターン目で「ヨシキ」という名前を覚えている時点で、チェックポインターが正しく機能していることが確認できます。
n8nの実装と並べて見る
ここまで動いたところで、本記事の重要なポイントである「n8nとLangGraphの対応関係」を整理しておきます。
| n8nのノード | LangGraphの構成要素 |
|---|---|
| Chat Trigger | invoke() の呼び出し側 |
| AI Agent | chatbot ノード |
| Claude API(Credential) | ChatAnthropic |
| Simple Memory | MemorySaverチェックポインター |
| Session ID | thread_id |
n8nのSimple MemoryノードとLangGraphのMemorySaverの違いについて確認しておきます。
n8nのSimple Memory
「直近N件のメッセージを配列で保持する」シンプルな仕組みで、ウィンドウサイズを指定できます。
LangGraphのMemorySaver
「Stateそのもののスナップショットを thread_id ごとに保存する」仕組みで、メッセージだけでなく、Stateに含まれる全ての情報(中間変数やノードの実行状態など)が保存されます。
メモリの中身を覗いてみる
LangGraphのもうひとつの強みは「状態が観測可能である」という点です。チェックポインターに保存されている内容を、コードから直接覗くことができます。
対話ループの中に1行追加してみます。
result = graph.invoke(
{"messages": [HumanMessage(content=user_input)]},
config=config,
)
# 追加:Checkpointerに保存されている全メッセージを表示
snapshot = graph.get_state(config)
print("--- メモリの中身 ---")
for msg in snapshot.values["messages"]:
print(f" [{type(msg).__name__}] {msg.content[:60]}...")
print("--------------------\n")
print(f"Claude: {result['messages'][-1].content}\n")
これで毎ターンごとに、Checkpointerが保持しているメッセージ履歴が表示されるようになります。
— メモリの中身 —
[HumanMessage] こんにちは。私の名前はヨシキです。…
[AIMessage] こんにちは、ヨシキさん。はじめまして…
[HumanMessage] 私の名前を覚えていますか?…
[AIMessage] はい、ヨシキさんですね。先ほどお名前を伺いました。…
——————–
n8nのSimple Memoryでは見えない部分が、LangGraphでは直接触れる、というのが大きな違いです。何かおかしな挙動をしたときに「メモリに何が入っているのか」を直接見て調査できるため、デバッグが簡単になります。
つまずいた箇所のメモ
実装中につまずいた箇所を共有しておきます。同じことで悩む方の参考になればと思います。
過負荷エラー(529)
API呼び出しが OverloadedError: Error code: 529 で失敗することがありました。これはAnthropic側のサーバーが一時的に混雑しているときに返されるエラーです。コードに問題があるわけではなく、しばらく待つか ChatAnthropic に max_retries=3 を追加することで対応できます。
llm = ChatAnthropic(
model="claude-sonnet-4-6",
max_tokens=1024,
max_retries=3, # 自動リトライを有効化
)業務利用するなら、このリトライ設定は必須と考えたほうがいいでしょう。
thread_idの指定忘れ
invoke の config 引数で thread_id を渡し忘れると、Checkpointerが機能せず毎回会話がリセットされます。エラーは出ないので気付きにくいですが注意が必要です。
次回予告とAnthropic SDKとの使い分け
本記事ではLangGraphを使った最小構成を実装しましたが、次回は同じ要件をAnthropic SDKを直接呼んで実装する記録を公開予定です。フレームワークが裏で何をしていたかをコードを書いて理解する、というアプローチで進めます。
最後に、実務での使い分けについて当社の見解を書いておきます。
中小企業の業務自動化レベルであれば、基本的にはn8nで十分だと考えています。GUI上でフローを組めて、メンテナンス担当者が変わっても引き継ぎやすく、コードも最小限で済みます。
ある程度複雑なエージェント(条件分岐が深い、状態管理が複雑、人間のレビューを挟むワークフローなど)を組む必要があるなら、LangGraphが選択肢に入ります。グラフ構造で見通しが良く、状態の可観測性も高いため、複雑になっても破綻しにくい設計です。
エージェントの挙動を完全に制御したい、依存ライブラリを最小化したい、というケースではAnthropic SDKを直に使用する設計となります。コード量は増えますが、ブラックボックスがゼロになるため、トラブルシューティングや細かいチューニングが圧倒的にやりやすくなります。








コメント